Workflow 1
Small labeled sample, large unlabeled sample
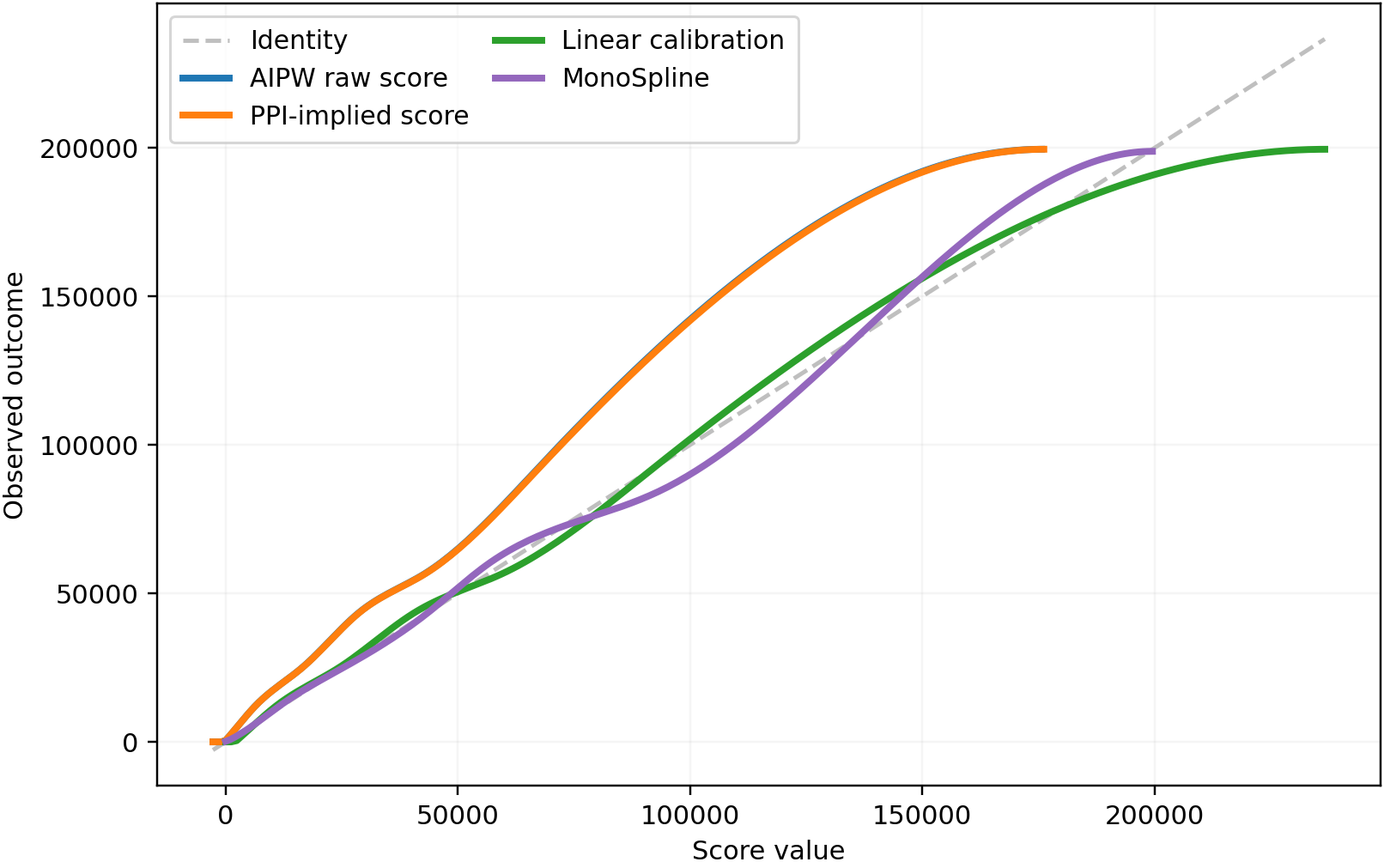
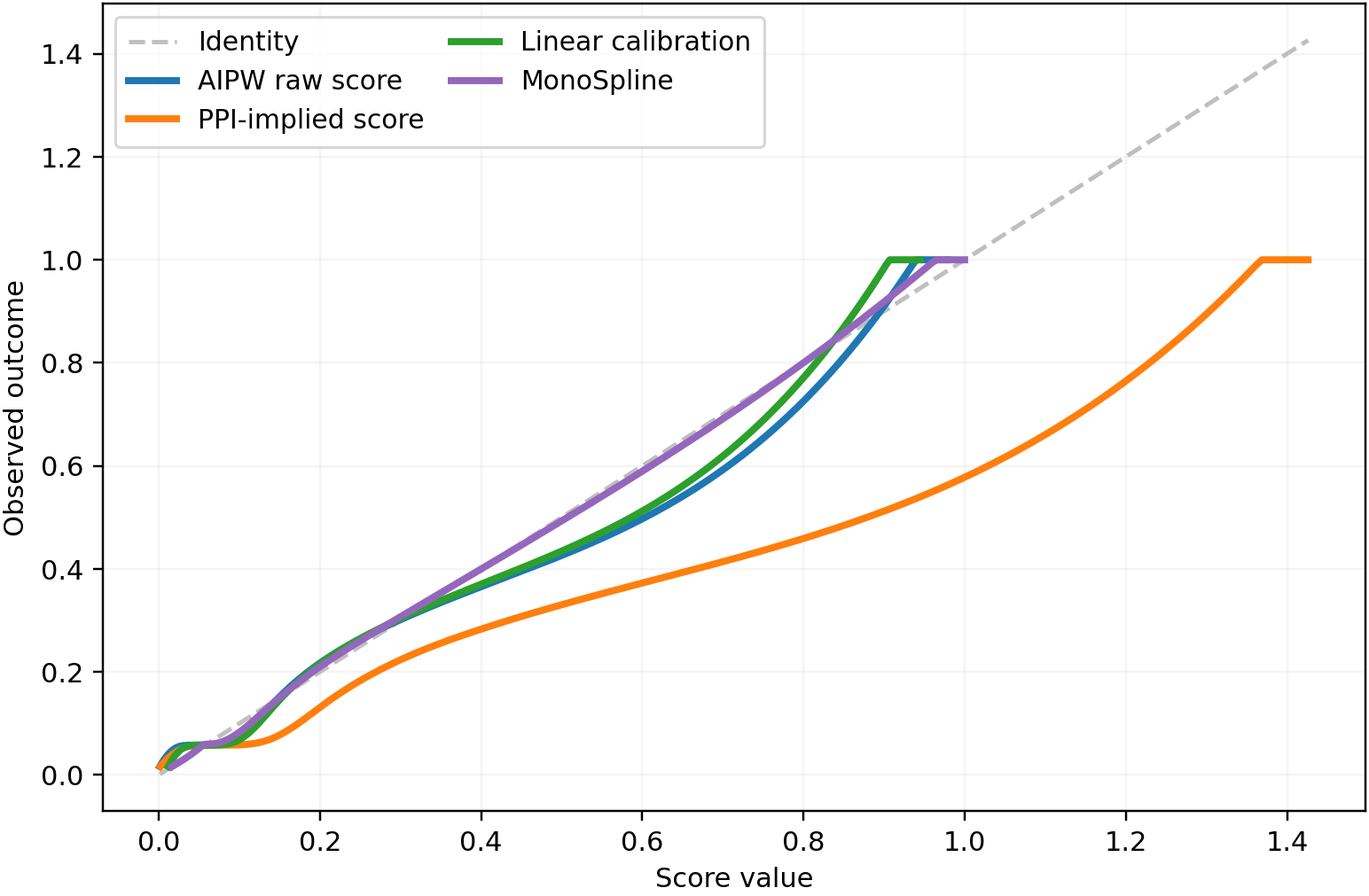
Standard semisupervised mean setting: observed outcomes on a small labeled sample, predictions on labeled and unlabeled rows, and one mean to estimate.
Main call: mean_inference(...)
Python
mean_inference(Y, Yhat, Yhat_unlabeled, ...)
R
mean_inference(Y, Yhat, Yhat_unlabeled, ...)